Synapses
The Synapse update is the first major update to the Bittensor Network.
By introducing synapse architecture, we have enabled the compression and transmission of logits, which dramatically improve both validation accuracy and overall network efficiency. The update also allows clients of the network to run inference directly - decode rich embeddings and directly generate text - while opening up further possibilities for future task-specific synapses to perform text-generalization, image generation, and other AI-specific tasks. Additionally, we have updated Validator evaluation criteria and implemented the use of scaling laws to optimize validation capabilities even further.
In a nutshell, the Synapse update:
- allows our network to interface seamlessly with the outside world
- opens up further possibilities for innovation and extensibility
- increases the overall modularity, performance and utility of the network as a whole
Problem Statement:
Prior to the update, the network transmitted next-token embedding of size (Batch, Seq, Network) between Validators and Servers. This meant that each Server needed to reply with their last hidden state and transmit their embeddings, E(x) over the wire. Validators then passed these embeddings through their own decoder and computed the cross-entropy loss, CE from the predicted logits. The origin of this approach in the context of our project was that it made use of the mixture-of-experts model, one of the initial inspirations for the Bittensor Network.
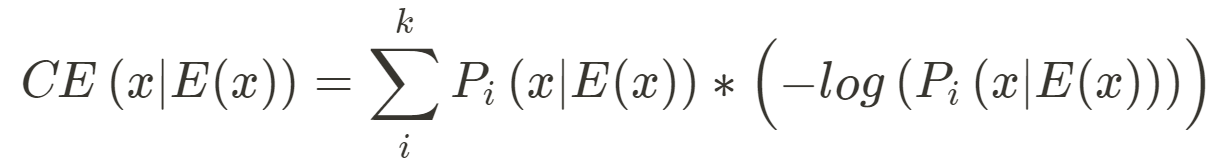
There were some key advantages to this approach.
Working in the embedding space allowed us to mix and match embeddings from different Servers, which enabled us to discover synergy across unconventional pairings. Embeddings also supported multi-modal/model combinations that allowed the network to solve various problems.
However, there was a significant drawback.
The use of embeddings didn't create an optimal distribution of duties between Servers and Validators. By working in the embedding space, Validators were responsible for training a decoder to decode received embeddings into logits for evaluation, and while this was possible with a smaller network, with expansion this task became overly time-consuming. The result of this was a potential loss of evaluation accuracy for Validators, and therefore a loss in overall network efficiency and value creation.
The Synapse update comprises three main network changes:
Embeddings to logits
With the update, we transitioned from the use of embeddings to directly transmitting token logits over the wire. This means that Servers are now responsible for using/developing their own decoder to compute the probabilities of the next-token logits of size (Batch, Seq, Vocab). These logits are then translated and compressed before transportation to Validators. The result of this is that Validators no longer have to use a decoder and can directly evaluate incoming logits, dramatically improving the accuracy of their assessments while allowing the network to scale more efficiently.
Task-specific synapses
The shift from embeddings to logits has also allowed us to add additional frameworks to the protocol, through the introduction of synapse objects to the Bittensor API. Synapse objects enable communication between Validators and Servers concerning which tasks capability and information format is expected. We are initially releasing three types of synapses, with more to be released in the near future.
TextLastHiddenState
The embedding synapse.
This synapse emulates the prior state of our network.
TextCausallm, TextCausallmNext
The logit synapse.
Communicates the expectation that a Server will perform NTP and return a probability distribution containing the most probable logits. Post update, these are the main evaluation synapses in the network.
TextSeq2seq
The generation synapse.
Rather than NTP, this synapse communicate the expectation of text generation given a prompt.
Additional integrations
Evaluation Criteria
We have shifted Validator evaluation from one based on a collective measurement to one based on individual assessment. Before the update, we used a modified version of shapely scores, a collaborative game-theory method to distribute contributions. Essentially, a Server, i, is scored based on its contribution to the group by measuring the difference in cross-entropy loss with and without embeddings. This method of evaluation allowed us to reward innovative and collaborative models that added unique value to the overall collective, N.
The drawback of this method, was, however, that as the network expanded, this type of scoring punished duplicated/similar models, resulting in fluctuating and inconsistent scores for more common types. As such, we found that a more individual assessment approach was optimal.
Scaling Laws
Secondly, we added a scaling laws, S, that can distinguish larger language models with potential to achieve state-of-the-art machine intelligence. Scaling laws take into account the difficulty of achieving the last 10% of of SOTA machine intelligence and rewards Servers accordingly by distinguishing which factors (dataset size, computational budget, number of parameters) are leading to improvements in models performance.
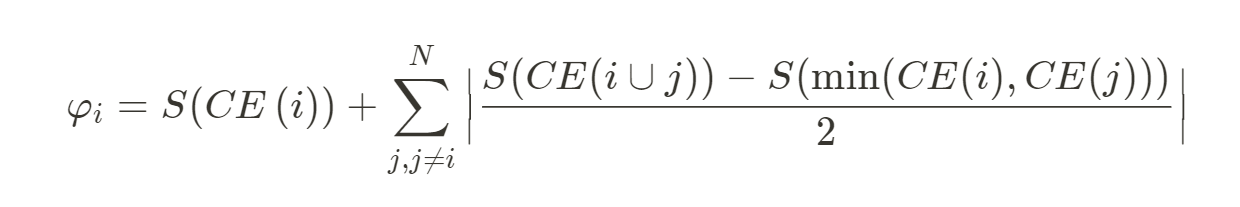
Ultimately, the implementation of the Synapse update is set to dramatically increase the utility, efficiency and modularity of the network as a whole, by allowing a seamless and dynamic transmission of information in and out of the ecosystem fit for a wide variety of use cases. This opens up possibilities for both internal and external innovation, extensibility and expression, some of which are immediately obvious, and some of which have yet to be discovered.